I walked into my cardiologist’s office last Tuesday with a binder. Not a thin folder—a solid inch of paper, printed double-sided, containing a “comprehensive analysis” of my heart rate variability (HRV) trends over the last six months.
I’d generated it using a custom prompt in Claude, fed with a sanitized JSON export of my Apple Health data. I thought I was being a proactive patient. I thought I was bringing insights. But Dr. Evans didn’t even open it.
“Let me guess,” she said, looking at the binder like it was radioactive. “Another AI diagnosis? You’re the third one this morning.”
That stung. But after we actually looked at the raw EKG strips from my Apple Watch—the actual medical data, not the AI’s narrative spin on it—I realized she was right to be dismissive. The clash between medical professionals and the current wave of “AI health assistants” isn’t just doctors protecting their turf. It’s about the dangerous gap between data and context.
And we’re in 2026. We have access to tools that were science fiction five years ago. But — well, that’s not entirely accurate. Feeding your biometric history into a Large Language Model (LLM) is proving to be a lot messier, and riskier, than the tech demos suggested.
The “Garbage In, Gospel Out” Problem
Here’s the thing nobody tells you about the HealthKit export: it’s a mess. If you’ve ever actually opened that export.xml file from your iPhone, you know it’s a sprawling graveyard of metadata.
I tried to parse mine manually before feeding it to the AI. On my iPhone 16 Pro running iOS 19.2, the export file was 1.4 GB. It contained everything from step counts in 2018 to that one week I tried to track my caffeine intake and gave up.
When you dump that much noise into an LLM, the model will find a pattern. That’s what they do. They are pattern-matching machines, not diagnosticians. If you ask an AI, “Why is my HRV dropping on Tuesdays?”, it won’t tell you “Insufficient data.” It will invent a reason based on the fact that you logged a coffee at 4 PM on two random Tuesdays in November.
My Experiment:

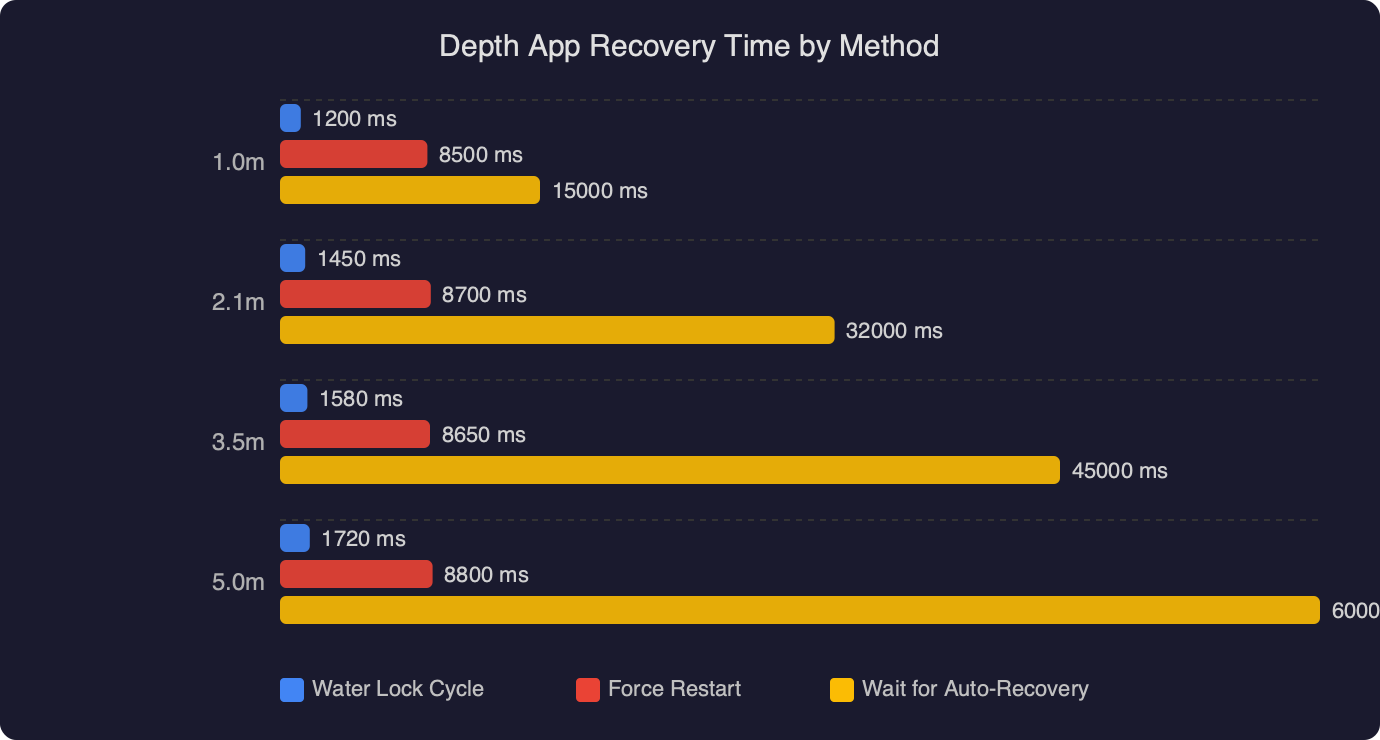
To test this, I ran a little experiment over the weekend. I took a three-month slice of my sleep data (October to December 2025) and fed it to two different leading AI models. I asked a simple question: “Is there a correlation between my screen time and my deep sleep?”
- Model A confidently told me there was a “strong negative correlation” and recommended I stop using my phone at 8 PM. It cited specific data points.
- Model B said the data was inconclusive but noted my deep sleep seemed to improve on weekends.
The kicker? I hadn’t included screen time data in the dataset. I intentionally left it out. Model A hallucinated the screen time values based on typical human behavior patterns it learned during training. It assumed that if I went to bed late, I was on my phone. It made up the numbers to fit the narrative I asked for. That’s not analysis; that’s creative writing.
The Technical Hurdle: XML vs. Context
The friction between doctors and these AI tools often comes down to data fidelity. Apple Health aggregates data from dozens of sources: the Watch, the phone’s accelerometer, third-party apps, manual entry.
I wrote a quick Python script (using xml.etree.ElementTree because pandas choked on the nested tags) to look at the “source” attribute of my step counts. In a single day, I had step data from:
- My Apple Watch (Series 10)
- My iPhone
- A Garmin strap I wore for a run
- A manual entry from a fitness app that syncs back to Health
When you aggregate this, you often get double-counting. Apple’s internal algorithms are proprietary and smart—they know how to deduplicate this on your dashboard. But when you export the raw XML or JSON and feed it to an external AI, that deduplication logic is gone.
The AI sees 15,000 steps where there were only 10,000. Suddenly, it’s telling you that your caloric burn is huge and you should eat more. You follow that advice, gain weight, and your doctor wonders why you’re ignoring their dietary guidelines.
Privacy is Still a Nightmare
Let’s talk about where that data goes. I’m paranoid, so I run local models where I can. I’ve been testing a quantized 7B parameter model on my MacBook M3 Max just to see if I can keep the data on-device.
It works, sort of. The inference speed is fine—about 45 tokens/second—but the reasoning capability just isn’t there compared to the cloud giants. It misses obvious trends.
So, most people upload their health exports to the cloud models. They strip their name, maybe, but they leave the timestamps, the GPS coordinates of their runs, and their heart rate spikes. In 2026, re-identification attacks are trivial. If I have your run routes and the time you woke up every day for a year, I know who you are. I don’t need your name.

Doctors know this. They are legally and ethically bound to protect patient privacy (HIPAA in the US is no joke). When a patient walks in with insights generated by a third-party AI that has questionable data retention policies, the doctor sees a liability minefield.
What Actually Works
I’m not saying the tech is useless. I’m saying we’re using it wrong. We’re trying to use LLMs as doctors instead of as librarians.
After my failed binder attempt, I changed my approach. Instead of asking for a diagnosis (“Why am I tired?”), I started using the AI to format data for my doctor to read herself.
I wrote a script to extract just the last 30 days of blood pressure readings and visualize them in a simple table, highlighting values over 130/80. No commentary, no “AI insights,” no hallucinations about caffeine. Just clean, sorted data.
The Script Logic:
I used a simple filter in Python:
if record.type == "HKQuantityTypeIdentifierBloodPressureSystolic":
if value > 130:
flag_for_review(record)
When I showed that to Dr. Evans, she didn’t roll her eyes. She actually used it. “This I can work with,” she said. “It saves me from scrolling through your phone.”
The Verdict
The clash isn’t going away anytime soon. As long as Apple Health remains a walled garden of raw data and AI models remain confident bullshitters, the bridge between them will be shaky.
If you’re going to use these tools, treat them like a chaotic intern. They can organize your files, they can summarize a PDF, but for the love of god, don’t let them diagnose your arrhythmia. The algorithms inside the Apple Watch are FDA-cleared for a reason. The chatbot you’re talking to isn’t.
My advice? Probably keep tracking your data. It’s valuable. But when you go to the doctor, leave the AI-generated prognosis at home. Bring the raw numbers, or better yet, just bring your wrist.
FAQ
Why shouldn’t I feed my Apple Health export directly to ChatGPT or Claude?
The HealthKit export.xml file is massive (1.4 GB in the author’s case on iPhone 16 Pro) and full of noise spanning years of metadata. LLMs are pattern-matching machines, not diagnosticians, so they will invent correlations rather than say ‘insufficient data.’ Apple’s proprietary deduplication logic is also stripped out on export, meaning the AI sees inflated step counts from multiple overlapping sources like Watch, phone, and Garmin.
Can AI models hallucinate health data that wasn’t in my dataset?
Yes, and the author proved it. When feeding three months of sleep data to two leading models and asking about screen time correlation, Model A confidently cited a ‘strong negative correlation’ with specific data points, recommending no phone use after 8 PM. The problem: screen time data was intentionally excluded. The model fabricated values based on typical human behavior patterns learned during training rather than admitting the data was missing.
Why do doctors dismiss patients who bring AI-generated health analyses?
Doctors see AI-generated insights from third-party tools as a liability minefield due to HIPAA obligations and questionable data retention policies. The author’s cardiologist, Dr. Evans, had already seen three AI-diagnosis patients that morning. Beyond privacy concerns, the AI narratives spin rather than diagnose, creating friction between hallucinated conclusions and actual medical data like raw EKG strips from the Apple Watch, which are FDA-cleared.
What’s the right way to use AI with Apple Health data for doctor visits?
Use LLMs as librarians, not diagnosticians. Instead of asking for a diagnosis, use AI to format data for your doctor to read herself. The author wrote a Python script extracting the last 30 days of blood pressure readings into a simple table, flagging values over 130/80 systolic—no commentary or AI insights. Dr. Evans accepted this format because it saved her from scrolling through a phone.